Legend: Definitions, Terms, <Text>, [IPA], -Tags-, and "Glosses".
Jul23/C6 has no phonology (in the strict sense). What it has instead of sounds are numeric values in the range 0 to 127 decimal; these are called original codes. Sequences of them form morphemes, which form words; there are also some non-morphemic codes, such as (space), which are used as word separators, etc. The classes of codes are shown in the following table, along with their value ranges:
| First | Last | Size | Name |
|---|---|---|---|
| 0 | 7 | 8 | numeric (octal) |
| 8 | 23 | 16 | particles |
| 24 | 63 | 40 | other (affixes & clitics) |
| 64 | 73 | 10 | pronominal (affixes & clitics) |
| 74 | 74 | 1 | quote |
| 75 | 75 | 1 | escape |
| 76 | 79 | 4 | non-token |
| 80 | 127 | 48 | alphabetic |
A numeric morpheme consists of a sequence of 1 or more numeric class codes.
A string morpheme consists of a possibly empty sequence of codes preceded and followed by quote codes. The escape code appears immediately before an otherwise non-quotable code in order to quote that code. The non-quotable codes include the quote and escape codes.
An identifier morpheme consists of 2-3 alphabetic codes. If the middle bit of the 1st alphabetic code's binary value is 0, there are only 2 alphabetic codes; otherwise there are 3.
A particle morpheme consists of a single particle code, a pronominal morpheme consists of a single pronominal code, and an other morpheme consists of a single other class code. Non-token codes are also non-combining.
The orthography uses the 95 ASCII characters from 32 (space) through 126 (~). Space, hyphen (-), and possibly a couple others are used as separator characters corresponding to the original code separators.
Numeric tokens are represented by sequences of octal digits (0-7) and are always preceded by a distinguishing token. For cardinal numbers, this token is an asterisk (*). For fractional numbers, this token is a slash (/). For ordinal numbers, this token is a hatch (#). Single decimal digits (0-9) are also used for representing pronominal affixes and index assignment clitics. An apostrophe (') is inserted between a numeric token and a pronominal suffix.
Quoted strings are formed using possibly empty sequences of ASCII characters enclosed in quotes (both "). The escape character (') appears immediately before an otherwise non-quotable character in order to quote that character. The non-quotable character include the quote and escape characters.
Principal identifiers are sequences of 2 letters, the 1st of which is lower case (a-x). Additional identifiers are sequences of 3 letters, the 1st of which is upper case (A-X). Each particle is represented by a single lower case letter preceded by a period (.). In many cases, an affix (both inflectional and derivational) is represented by a single upper case letter preceded by a period (.).
Other affix and clitic tokens are represented by single non-alphanumeric characters.
The characters (, ` y z Y Z) aren't used.
The following table shows the mapping for each original code. The row labels give the 4 most significant bits (in octal) while the column labels give the 3 least significant bits (in octal). The entries give the ASCII characters and sequences for each, along with the interlinear tags (where they exist).
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Orth | Tag | Orth | Tag | Orth | Tag | Orth | Tag | Orth | Tag | Orth | Tag | Orth | Tag | Orth | Tag | |
| 00 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||||||||
| 01 | .s | Seq | .c | Sim | .d | Dis | .i | If | .r | Rat | .t | Tmp | (free) | .x | Mir | |
| 02 | .n | EN | .p | EP | .w | Wit | .h | Hrs | .j | Jus | .m | Imp | .q | PQ | .f | Fin |
| 03 | .D | Deg | .C | Cmp | .S | Sup | .E | Sat | .Q | QP | .B | BP | .L | LP | .T | TP |
| 04 | .M | Man | .U | Mas | .N | Inh | % | Hab | \ | Aor | @ | Prg | [ | Pro | ] | Prf |
| 05 | .I | Inch | .O | Term | .V | Inv | ; | Nom | ^ | Neg | = | Eq | < | LT | > | GT |
| 06 | .R | Rec | $ | Def | & | Ind | ~ | NR | ? | CQ | ! | Rem Dist |
{ | Ana Medi |
} | Cat Prox |
| 07 | : | P | # | Ord | * | N | / | D | + | Agg | | | Alt | ( | Fut | ) | Pst |
| 10 | 0 | Uns | 1 | 1 | 2 | 2 | 3 | 3A | 4 | 3B | 5 | 3C | 6 | 3D | 7 | 3E |
| 11 | 8 | Rfx | 9 | Inc | " | Quo | _ | Esc | (space) | (hyphen) | (delimiters) | |||||
| 12 | a | b | c | d | e | f | g | h | ||||||||
| 13 | A | B | C | D | E | F | G | H | ||||||||
| 14 | i | j | k | l | m | n | o | p | ||||||||
| 15 | I | J | K | L | M | N | O | P | ||||||||
| 16 | q | r | s | t | u | v | w | x | ||||||||
| 17 | Q | R | S | T | U | V | W | X | ||||||||
The following is a possible alternate writing system. It allows values from 0 to 255 (decimal) to be written with a single glyph. Each symbol is composed of 3 components: 1 from each line, representing the octal digits. The top row shows the least significant digit components and the bottom row shows the most significant digit components. The image also shows a sample combination.
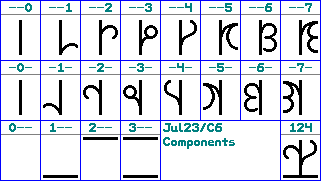
There are 2 ways to use these symbols: as purely numeric, using all of them, or as codes, using only the 1st 128 (in which case each digit of a numeric morpheme is written separately).
page started: 2015.Jul.31 Fri
current date: 2015.Aug.12 Wed
content and form originated by qiihoskeh
Table of Contents